采集功能可以抓取页面信息,作为文章保存到系统。注意:具有反采集措施的网站,无法采集。
采集列表
点击后台 互动 - 采集管理 进入采集列表页面。
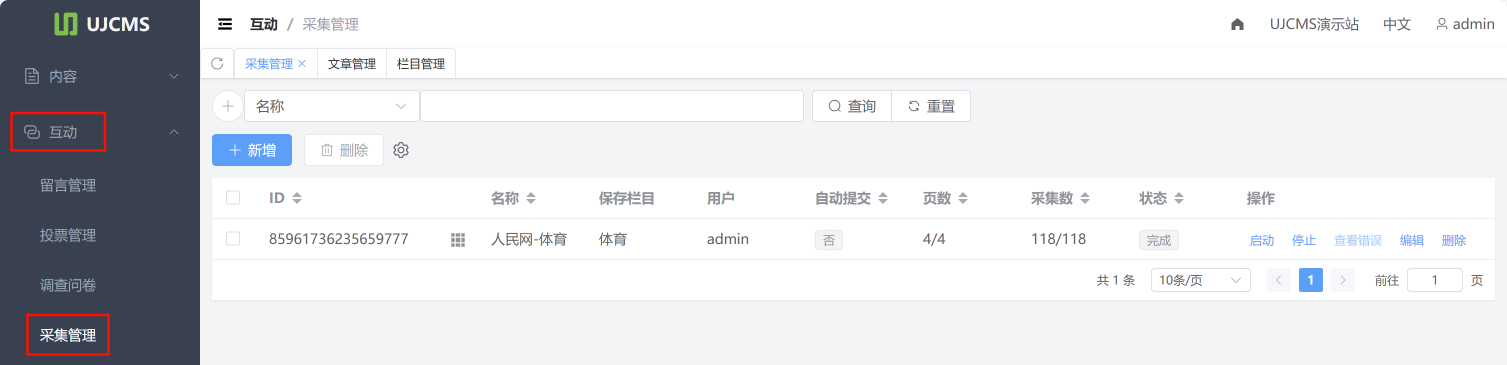
采集新增
点击 新增 按钮,填写采集基础信息。
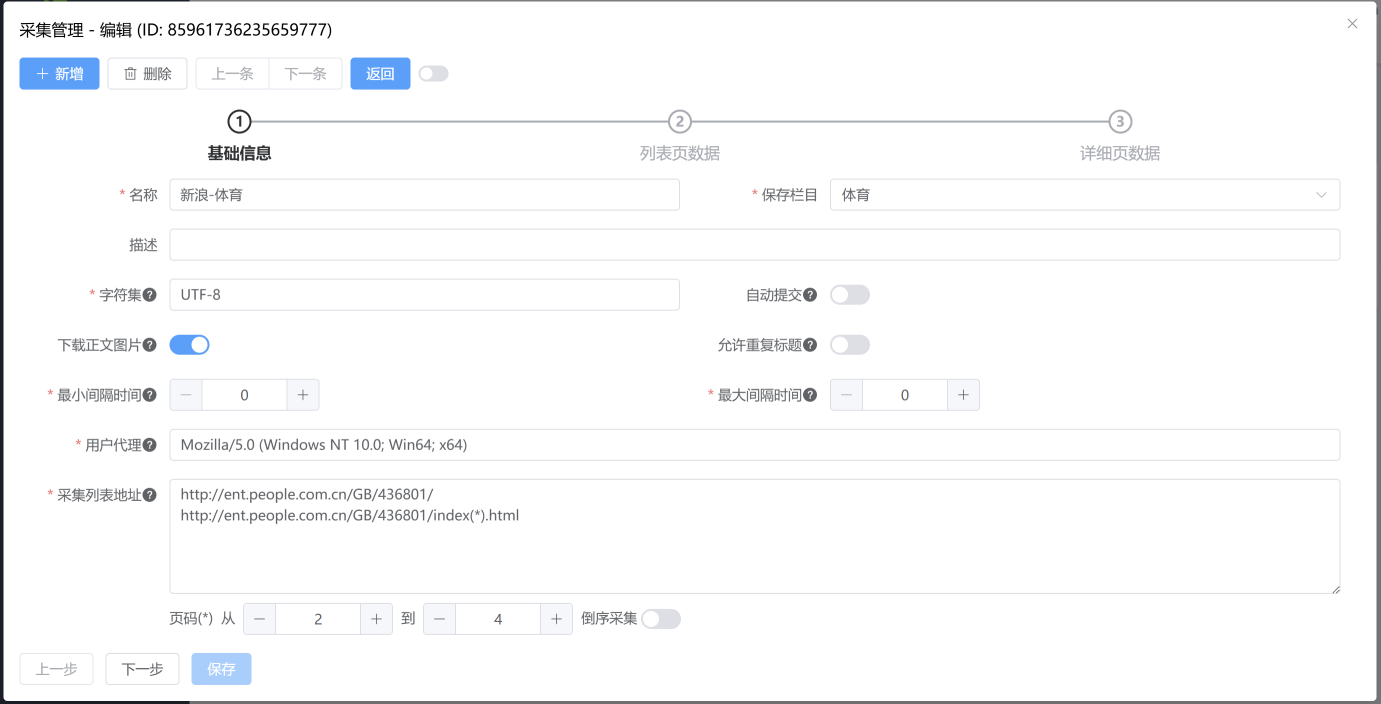
保存栏目:采集到的文章保存到哪个栏目。
字符集:指待采集页面的字符集,通常为 UTF-8,设置错误可能导致乱码。可以在浏览器中点击右键,再点 "查看页面源代码",找到类似 <meta http-equiv="content-type" content="text/html;charset=UTF-8"/> 的代码。
采集列表地址:包含文章详细页链接的列表页地址。一行一条,可以使用 (*) 代替页码。如:
http://ent.people.com.cn/GB/436801/
http://ent.people.com.cn/GB/436801/index(*).html第一条为列表首页地址,第二条为 2 到 4 页的列表页地址。
采集列表页数据
点击 下一步 按钮,填写采集列表页数据。
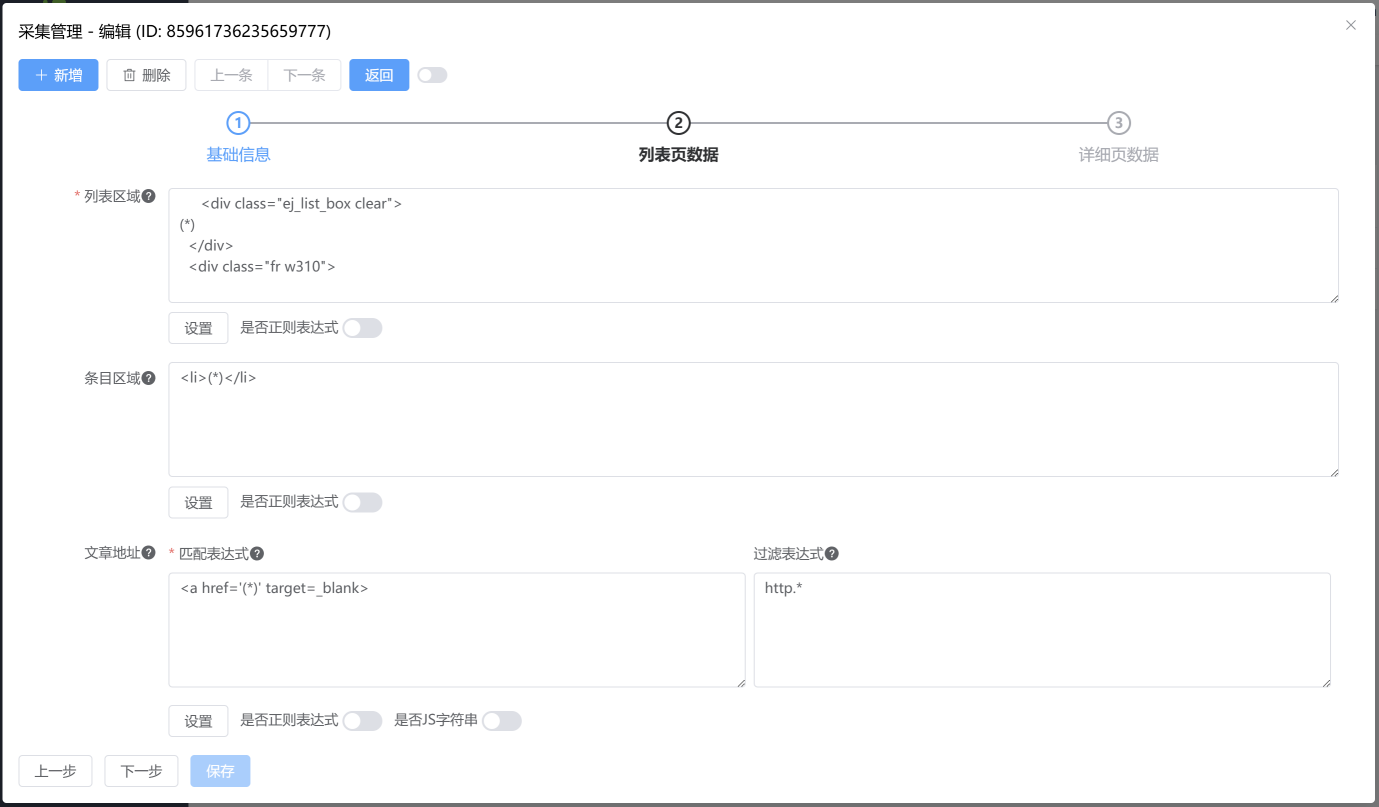
可以点击 设置 按钮,进入设置页面。
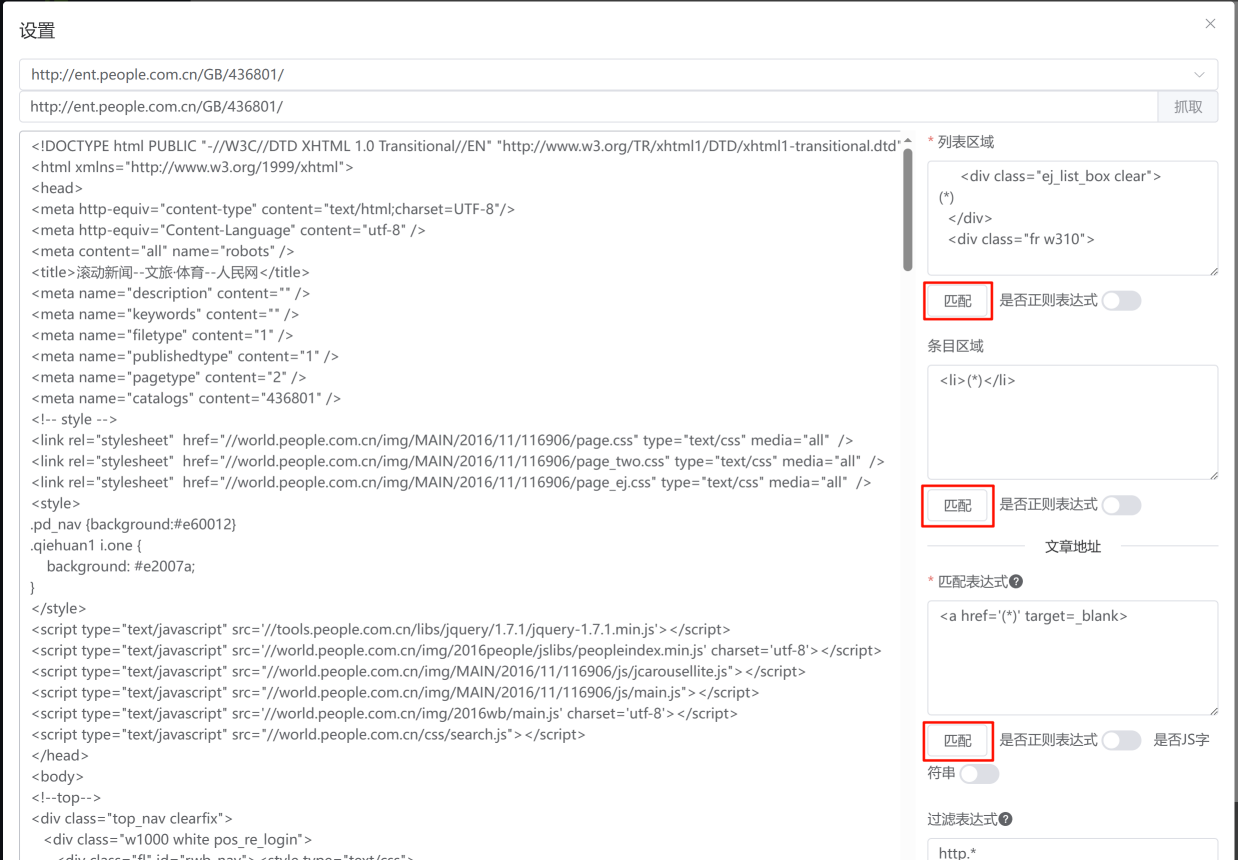
填写匹配规则后,从上至下依次点击 匹配 按钮,可获得最终结果。最终结果通常为一行一条的文章详细页 URL 地址。
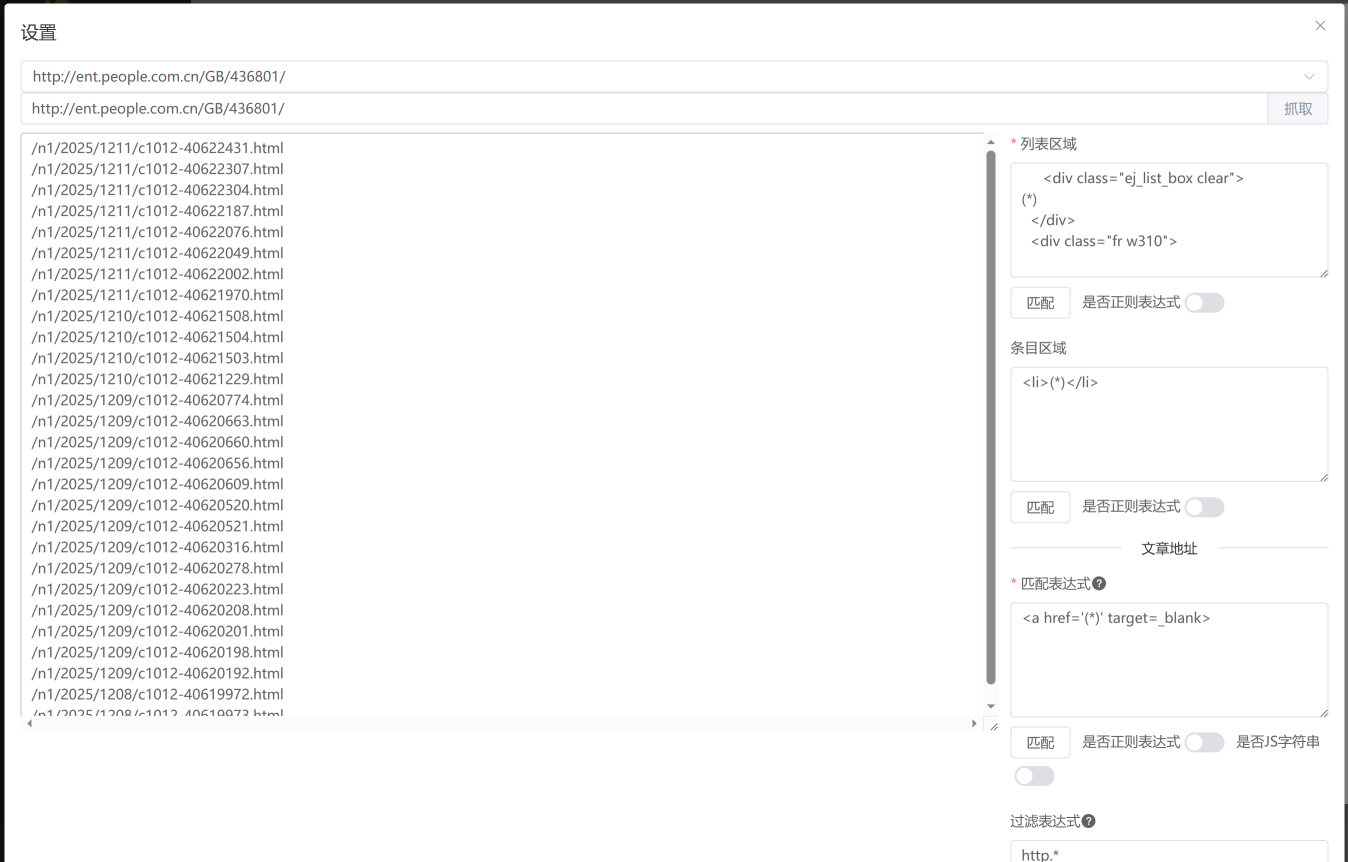
如匹配结果不符合预期,可以点击上方 抓取 按钮,重新获取页面内容。
是否正则表达式:默认使用 (*) 获取匹配内容。如开启正则表达式,则按照 Java 正则表达式获取匹配内容,如 ([\w\W]*)。使用正则表达式需要专业的知识,只适合对 Java 正则表达式规则精通的使用者。
是否 JS 字符串:如果匹配的内容是 JS 代码中的内容,需勾选该项。如为正常的 HTML 内容,则无需勾选。
列表页代码
在浏览器中查看列表页的页面源代码,假设有如下结构:
<html>
...
<ul class="list-style">
<li><a href="/path/example1.html" target="_blank">标题1</a></li>
<li><a href="/path/example2.html" target="_blank">标题2</a></li>
<li><a href="https://www.other-site.com/path/example1.html" target="_blank">其它标题2</a></li>
<li><a href="/path/example3.html" target="_blank">标题3</a></li>
....
</ul>
...
</html>列表区域
列表区域包含所有文章详细页 URL 地址的区域。此例为 <ul class="list-style"> ... </ul> 中的内容,匹配规则为:
<ul class="list-style">
(*)
</ul>匹配结果为:
<li><a href="/path/example1.html" target="_blank">标题1</a></li>
<li><a href="/path/example2.html" target="_blank">标题2</a></li>
<li><a href="https://www.other-site.com/path/example1.html" target="_blank">其它标题2</a></li>
<li><a href="/path/example3.html" target="_blank">标题3</a></li>
....条目区域
条目区域是可选项。应包含每条文章的 url 地址、标题以及标题图(如有)。此例为 <li> ... </li> 中的内容,匹配规则为:
<li>*</li>匹配结果为:
<a href="/path/example1.html" target="_blank">标题1</a>
<a href="/path/example2.html" target="_blank">标题2</a>
<a href="https://www.other-site.com/path/example1.html" target="_blank">其它标题2</a>
<a href="/path/example3.html" target="_blank">标题3</a>文章地址 - 匹配表达式
获取文章的 URL 地址。通常为 href 中的内容。此例的匹配规则为:
<a href="(*)"匹配结果为:
/path/example1.html
/path/example2.html
https://www.other-site.com/path/example1.html
/path/example3.html文章地址 - 过滤表达式
过滤表达式是对匹配表达式的结果作进一步处理,是可选项,通常无需填写。
此例中假设 https://www.other-site.com/path/example1.html 为其它网站的链接,不希望采集,可使用过滤表达式过滤该地址。
过滤表达式使用 Java 正则表达式规则,删除匹配内容,保留捕获组。如 <a href="/abc">(.*)</a>,则删除链接标签,保留链接文本。
此例填写:
http.*匹配结果为:
/path/example1.html
/path/example2.html
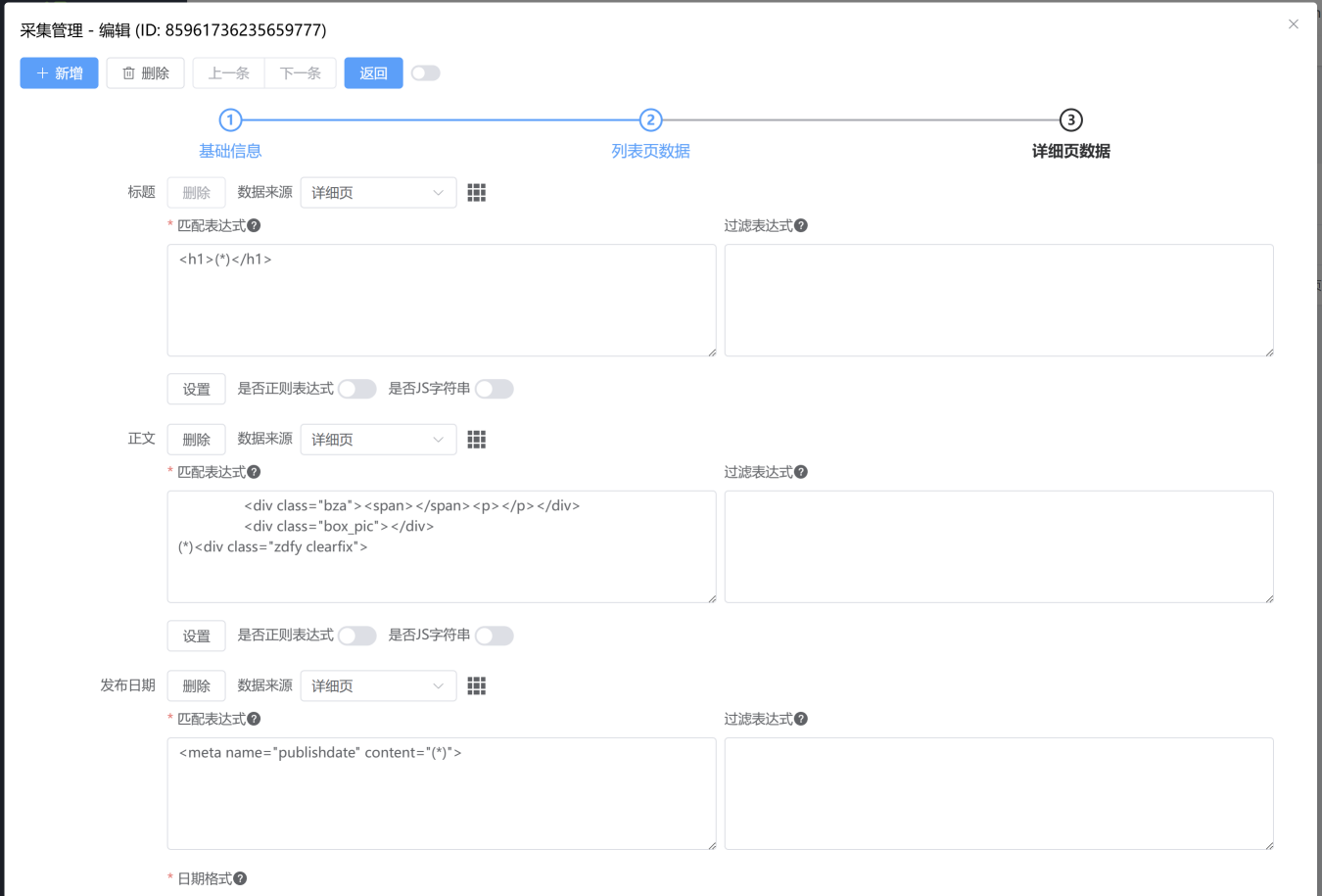
/path/example3.html详细页数据
在文章详细页中匹配各个字段,例如标题、正文、发布日期等。规则同上。


 赣公网安备 36010402000389号
赣公网安备 36010402000389号