如何将旧网站的数据导入到新网站中,从来都是一个重要且麻烦的问题。新旧网站的系统不一样,数据库表结构不一样,甚至连数据库类型都可能不一样。
UJCMS 提供数据迁移功能,能够一定程度上简化这个过程。但需要有专业的知识,能够写 SQL 语句,且对旧系统的表结构足够了解。
本迁移功能只可迁移栏目和文章数据,其它数据需要手动录入。数据迁移为一次性迁移,不可多次迁移或同步,多次迁移可能导致数据重复。
开启数据迁移功能
数据迁移功能默认是关闭的。需要使用时开启,使用完毕后关闭,以免误操作。
打开 /WEB-INF/classes/application.yaml 文件,开启数据迁移功能:
ujcms.dataMigrationEnabled: true修改完成后,重启 tomcat。
数据迁移界面
点击 系统 - 数据迁移 功能,即可进入数据迁移功能界面。如未发现此功能,请检测当前用户是否拥有该功能的权限(在角色管理中设置权限)、配置文件是否修改成功以及是否重启 tomcat。
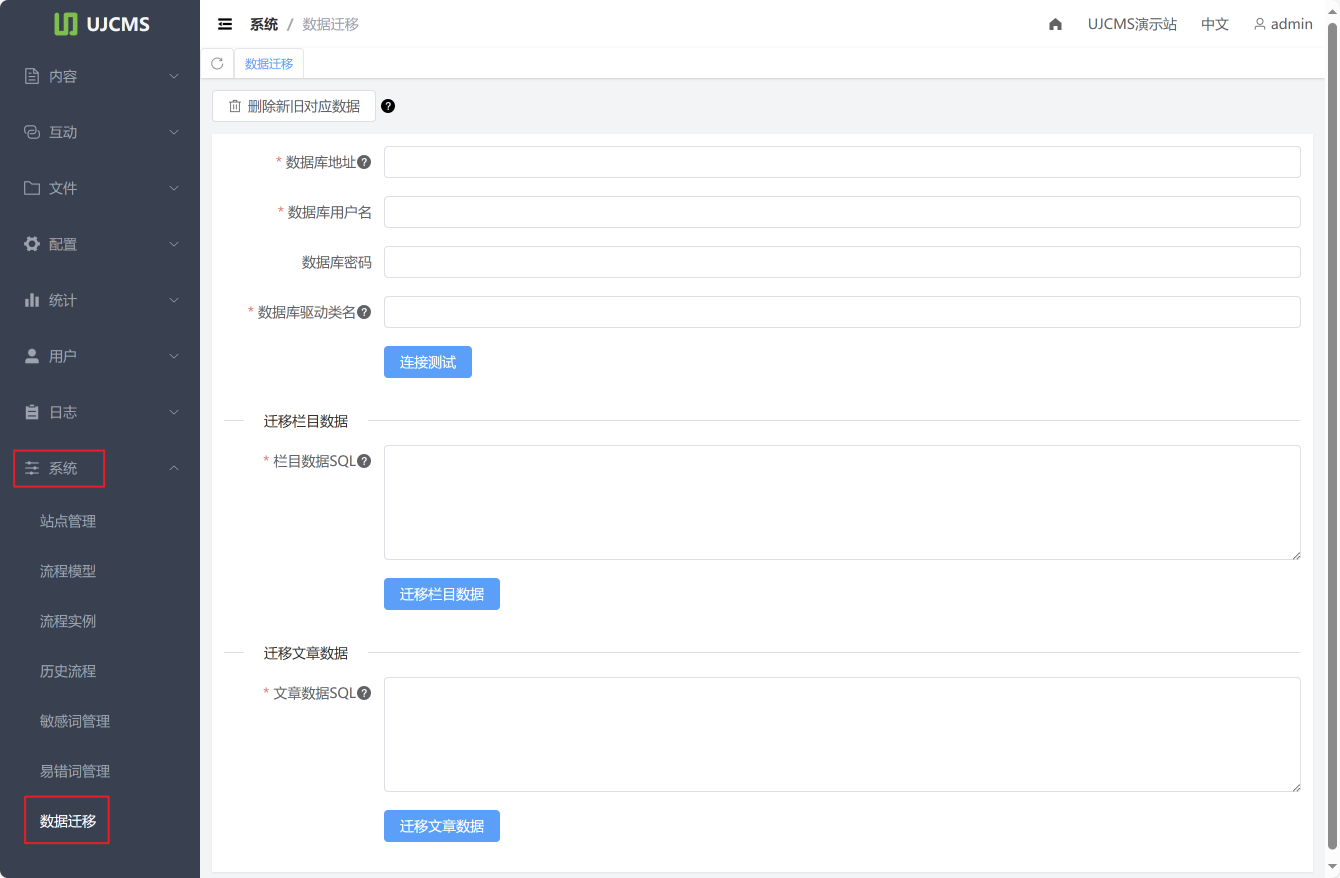
旧数据库地址
数据库地址:旧数据库的地址。不同数据库有不同的地址格式,请参考相应数据库的官方文档,并填写正确地址。
MySQL8:
jdbc:mysql://localhost:3306/ujcms?serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&nullCatalogMeansCurrent=trueMariaDB:
jdbc:mariadb://localhost:3306/ujcms?serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&nullCatalogMeansCurrent=truePostgreSQL:
jdbc:postgresql://localhost:5432/ujcms人大金仓数据库:
jdbc:postgresql://localhost:54321/ujcms达梦数据库:
jdbc:dm://localhost:5236/UJCMS
数据库用户名:数据库的登录用户名。
数据库密码:数据库的登录密码。
数据库驱动类名:不同数据库的驱动类名不一样。如系统中没有相应数据库的驱动,应将驱动 jar 文件复制到程序的 lib 目录下。
MySQL8:
com.mysql.cj.jdbc.DriverMariaDB:
org.mariadb.jdbc.DriverPostgreSQL:
org.postgresql.Driver人大金仓数据库:
org.postgresql.Driver达梦数据库:
dm.jdbc.driver.DmDriver
点击 连接测试,检测数据库连接是否正确。
迁移栏目数据
编写 SQL 从旧数据库中获取栏目数据。如:
select t.old_id as id_, t.old_name as name_ from old_channel t如果数据在多个表中,可以使用表连接等 SQL 语句(数据库支持的语法都可使用)。
数据迁移比较耗时,特别是数据量大的情况下,请耐心等待。
栏目字段列表
将旧数据库中的字段,通过 as 关键词对应到以下字段中,注意字段结尾的下划线 _ 不可省略。带 * 标记的为必须字段。
id_:*栏目IDparent_id_:上级栏目IDname_:*栏目名称alias_:栏目别名seo_title_:SEO标题seo_keywords_:SEO关键词seo_description_:SEO描述link_url_:跳转链接image_:栏目图片text_:正文markdown_:Markdownviews_:浏览次数created_:创建时间modified_:修改时间target_blank_:是否新窗口打开nav_:是否导航菜单type_:栏目类型 1:常规,2:单页,3:链接
迁移文章数据
需要先迁移栏目数据,再迁移文章数据,否则文章无法对应到栏目。
编写 SQL 从旧数据库中获取文章数据。如:
select t.old_id as id_, t.old_chanel_id as channel_id_, t.old_title as title_ from old_article t如果数据在多个表中,可以使用表连接等 SQL 语句(数据库支持的语法都可使用)。如果希望进行测试迁移,查看迁移效果,且原数据库数据量较大的,可在 SQL 语句中加上限制条数,如 MySQL 的 limit 语句。
数据迁移比较耗时,特别是数据量大的情况下,请耐心等待。
文章字段列表
将旧数据库中的字段,通过 as 关键词对应到以下字段中,注意字段结尾的下划线 _ 不可省略。带 * 标记的为必须字段。
id_:*栏目IDparent_id_:上级栏目IDchannel_id_:*栏目IDcreated_:创建时间modified_:修改时间publish_date_:发布时间status_:状态(0:已发布,1:已归档,10:草稿,20:已删除,21:已下线)title_:*标题subtitle_:副标题full_title_:完整标题link_url_:跳转链接target_blank_:是否新窗口打开seo_keywords_:SEO关键字seo_description_:SEO描述source_:来源image_list_json_:图片列表集(name:名称,url:图片URL,description:描述)file_list_json_:文件集(name:名称,url:文件URL,length:长度)image_:图片URLvideo_:视频URLvideo_orig_:原视频URLvideo_duration_:视频时长(单位:秒)audio_:音频URLaudio_orig_:原音频URLaudio_duration_:音频时长(单位:秒)file_:附件URLfile_name_:附件名称file_length_:附件大小(单位:字节)doc_:文库URLdoc_orig_:原文库URLdoc_name_:文库名称doc_length_:文库大小(单位:字节)text_:正文markdown_:Markdownviews_:浏览次数
删除新旧对应数据
导入栏目数据时,系统会记录旧数据库的栏目ID与新数据库的ID对应关系,方便下一步导入文章时找到对应的新栏目。
要进行全新迁移,且之前迁移过数据,应先 删除新旧对应数据。
如迁移数据后,发现未能符合预期,可将已迁移的栏目和文章数据删除,并删除新旧对应数据,再重新进行迁移。
jspxcms 迁移 ujcms 示例
栏目 SQL
SELECT
t.f_node_id AS id_,
t.f_parent_id AS parent_id_,
t.f_name AS name_,
t.f_number AS alias_,
td.f_meta_keywords AS seo_keywords_,
td.f_meta_description AS seo_description_,
td.f_link AS link_url_,
td.f_small_image AS image_,
tt.f_value as text_,
tm.f_value as markdown_,
t.f_views as views_,
t.f_creation_date as created_,
td.f_is_new_window AS target_blank_,
IF
( t.f_is_hidden = '0', TRUE, FALSE ) AS nav_
FROM
cms_node t
JOIN cms_node_detail td ON t.f_node_id = td.f_node_id
left join cms_node_clob tt on t.f_node_id = tt.f_node_id and tt.f_key = 'text'
left join cms_node_clob tm on t.f_node_id = tm.f_node_id and tm.f_key = 'text_markdown'文章 SQL
SELECT
t.f_info_id AS id_,
t.f_node_id AS channel_id_,
td.f_title as title_,
td.f_subtitle as subtitle_,
td.f_full_title as full_title_,
t.f_publish_date as publish_date_,
td.f_link as link_url_,
td.f_is_new_window as target_blank_,
(SELECT GROUP_CONCAT(tag.f_name SEPARATOR ',') FROM cms_info_tag tia join cms_tag tag on tag.f_tag_id = tia.f_tag_id where tia.f_info_id=t.f_info_id) as seo_keywords_,
td.f_meta_description as seo_description_,
td.f_source as source_,
td.f_small_image as image_,
td.f_video as video_,
td.f_doc_pdf as doc_,
td.f_doc as doc_orig_,
td.f_doc_name as doc_name_,
t.f_views as views_,
tt.f_value as text_,
tm.f_value as markdown_,
(case when t.f_status='A' then 0 when t.f_status='B' then 10 else 20 end) as status_
FROM
cms_info t
JOIN cms_info_detail td on t.f_info_id = td.f_info_id
left join cms_info_clob tt on t.f_info_id = tt.f_info_id and tt.f_key = 'text'
left join cms_info_clob tm on t.f_info_id = tm.f_info_id and tm.f_key = 'text_markdown'
jeecms 迁移 ujcms 示例
栏目 SQL
SELECT
t.channel_id AS id_,
t.parent_id AS parent_id_,
ext.channel_name AS name_,
t.channel_path AS alias_,
ext.keywords AS keywords_,
ext.description AS description_,
txt.txt AS text_,
IF
( txt.txt IS NULL, 1, 2 ) AS type_,
ext.is_blank AS target_blank_,
t.is_display AS nav_
FROM
jc_channel t
JOIN jc_channel_ext ext ON t.channel_id = ext.channel_id
LEFT JOIN jc_channel_txt txt ON t.channel_id = txt.channel_id文章 SQL
SELECT
t.content_id as id_,
t.channel_id as channel_id_,
ext.title as title_,
ext.release_date as publish_date_,
ext.link as link_url_,
ext.description as description_,
txt.txt as text_,
(select JSON_ARRAYAGG(JSON_OBJECT('name', attach.attachment_name, 'url', attach.attachment_path)) from jc_content_attachment attach where attach.content_id = t.content_id order by attach.priority) as file_list_json_,
(select GROUP_CONCAT(tag.tag_name SEPARATOR ',') from jc_contenttag ct join jc_content_tag tag on ct.tag_id = tag.tag_id where ct.content_id = t.content_id) as keywords_,
case
when t.`status` = 0 then 10
when t.`status` = 3 then 20
when t.`status` = 5 then 1
else 0
end as status_
FROM
jc_content t
JOIN jc_content_ext ext ON t.content_id = ext.content_id
LEFT JOIN jc_content_txt txt ON t.content_id = txt.content_id

 赣公网安备 36010402000389号
赣公网安备 36010402000389号